
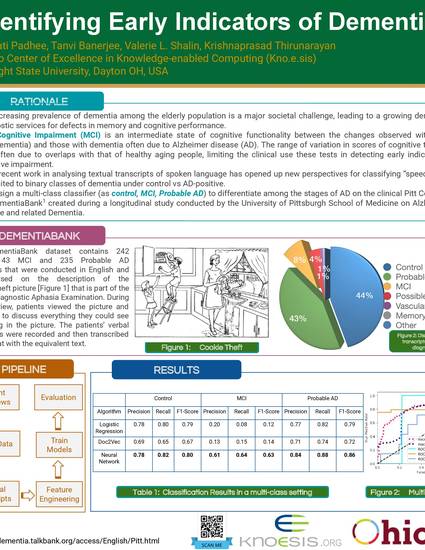
Alzheimer’s Disease (AD) is a degenerative chronic neurodegenerative disease that affects millions of people and whose care costs billions of dollars. There is growing evidence that variations in speech and language may be early indicators of dementia. One of the most initial symptoms of dementia is speech impairment, including difficulty in finding words and changes to the grammatical structure. These early indicators can be detected by having the patients perform a picture description task, such as the Cookie Theft task from the Boston Diagnostic Aphasia Examination. However, much of the state-of-the-art NLP for dementia has been limited due to the size of the available datasets. Understanding the vulnerability of linguistic features extracted from noisy text is essential for both developing better health text classification models and for interpreting the weaknesses of natural language models. This work explores the DementiaBank corpus of Cookie Theft picture descriptions to automatically detect dementia from speech and language translations. Inspired by the results of neuroscience studies, we explore the selective performance of lexical and syntactic features and present quantitative as well as qualitative evaluations.
Available at: http://works.bepress.com/tanvi-banerjee/39/