
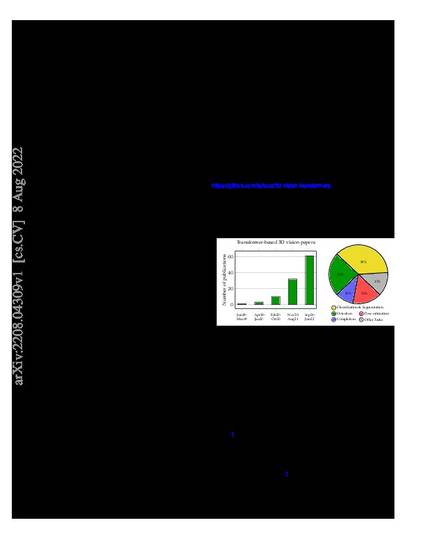
The success of the transformer architecture in natural language processing has recently triggered attention in the computer vision field. The transformer has been used as a replacement for the widely used convolution operators, due to its ability to learn long-range dependencies. This replacement was proven to be successful in numerous tasks, in which several state-of-the-art methods rely on transformers for better learning. In computer vision, the 3D field has also witnessed an increase in employing the transformer for 3D convolution neural networks and multi-layer perceptron networks. Although a number of surveys have focused on transformers in vision in general, 3D vision requires special attention due to the difference in data representation and processing when compared to 2D vision. In this work, we present a systematic and thorough review of more than 100 transformers methods for different 3D vision tasks, including classification, segmentation, detection, completion, pose estimation, and others. We discuss transformer design in 3D vision, which allows it to process data with various 3D representations. For each application, we highlight key properties and contributions of proposed transformer-based methods. To assess the competitiveness of these methods, we compare their performance to common non-transformer methods on 12 3D benchmarks. We conclude the survey by discussing different open directions and challenges for transformers in 3D vision. In addition to the presented papers, we aim to frequently update the latest relevant papers along with their corresponding implementations at: https://github.com/lahoud/3d-vision-transformers. © 2022, CC BY.
- 3D vision,
- point cloud,
- RGB-D,
- self-attention,
- survey,
- transformers,
- voxels,
- Benchmarking,
- Computer vision,
- Convolution,
- Data handling,
- Natural language processing systems,
- Network layers
Preprint: arXiv
Archived with thanks to arXiv
Preprint License: CC by 4.0
Uploaded 30 August 2022