
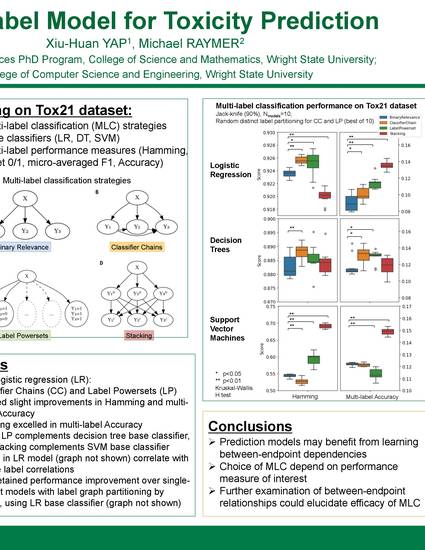
Most computational predictive models are specifically trained for a single toxicity endpoint. Since more than 1300 toxicity assays have been reported in the TOXCAST dashboard, achieving high coverage over this growing number of toxicity endpoints remains challenging. Furthermore, single-endpoint models lack the ability to learn dependencies between endpoints, such as those targeting similar biological pathways, which may be used to boost model performance. In this study, we characterize the performance of 3 multi-label classification (MLC) models, namely Classifier Chains (CC), Label Powersets (LP) and Stacking (SBR), on Tox21 challenge data. These MLC models employ the Problem Transformation approach, which is algorithm-independent and thus generally compatible with existing classifiers. Using Logistic Regression as the base classifier and random label partitioning (k=3), CC and LP show statistically significant improvement in model performance using Hamming and subset 0/1 scores (p
Available at: http://works.bepress.com/michael_raymer/110/