
Thesis
Degradation Specific OCR
(2010)
Abstract
Optical Character Recognition (OCR) is the mechanical or electronic translation of scanned images of handwritten, typewritten, or printed text into machine-encoded text. OCR has many applications, such as enabling a text document in a physical form to be editable, or enabling computer searching on a computer of a text that was initially in printed form. OCR engines are widely used to digitize text documents so that they can be digitally stored for remote access, mainly for websites. This facilitates the availability of these invaluable resources instantly, no matter the geographical location of the end user. Huge OCR misclassification errors can occur when an OCR engine is used to digitize a document that is degraded. The degradation may be due to varied reasons, including aging of the paper, incomplete printed characters, and blots of ink on the original document. In this thesis, the degradation due to scanning text documents was considered. To improve the OCR performance, it is vital to train the classifier on a large training set that has significant data points similar to the degraded real-life characters. In this thesis, characters with varying degrees of blurring and binarization thresholds were generated and they were used to calculate Edge Spread degradation parameters. These parameters were then used to divide the training data set of the OCR engine into more homogeneous sets. The resulting classification accuracy by training on these smaller sets was analyzed.
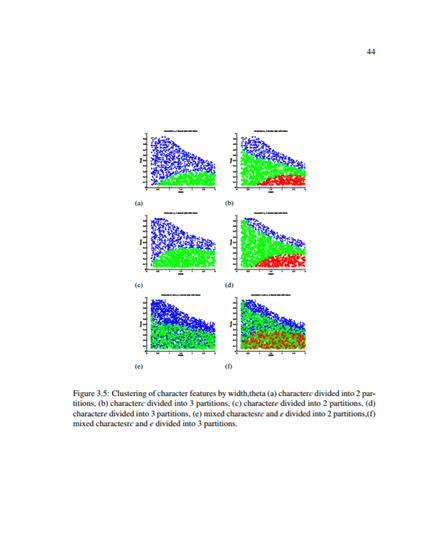
The training data set consisted of 100,000 data points of 300 DPI, 12 point Sans Serif font lowercase characters ‘c and ‘e’. These characters were generated with random values of threshold and blur width with random Gaussian noise added. To group the similar degraded characters together, clustering was performed using the Isodata clustering algoirithm. The two edge-spread parameters, one calculated on isolated edges named DC, one calculated on edges in close proximity accounting for interference effects, named MDC, were estimated to fit the cluster boundaries. These values were then used to divide the training data and a Bayesian classifier was used for recognition. It was verified that MDC is slightly better than DC as a division parameter. A choice of either 2 or 3 partitions was found to be the best choice for dataset division. An experimental way to estimate the best boundary to divide the data set was determined and tests were conducted that verified it.
Both crisp and fuzzy approaches for classifier training and testing were implemented and various combinations were tried with the crisp training and fuzzy testing being the best approach, giving a 98.08% classification rate for the data set divided into 2 partitions and 98.93% classification rate for the data set divided into 3 partitions in comparison to 94.08% for the classification of the data set with no divisions.
Keywords
- scanning degradation,
- synthetically degradated data,
- fuzzy bayesian classifier
Disciplines
Publication Date
December, 2010
Degree
Master of Science
Field of study
Electrical Engineering
Department
Electrical and Computer Engineering
Advisor
Elisa Barney Smith, Ph.D.; Thad Welch, Ph.D.; and Tim Andersen, Ph.D.
Citation Information
Subramaniam Venkatraman. "Degradation Specific OCR" (2010) Available at: http://works.bepress.com/elisa_barney_smith/25/